Assignment: Running a Classification Tree
15 Jan 2017Program and outputs
Data loading and cleaning
import pandas as pandas
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
import sklearn.metrics
import numpy as np
CSV_PATH = 'gapminder.csv'
data = pandas.read_csv(CSV_PATH)
print('Total number of countries: {0}'.format(len(data)))
Total number of countries: 213
PREDICTORS = [
'incomeperperson', 'alcconsumption', 'armedforcesrate',
'breastcancerper100th', 'co2emissions', 'femaleemployrate',
'hivrate', 'internetuserate', 'oilperperson',
'polityscore', 'relectricperperson', 'suicideper100th',
'employrate', 'urbanrate'
]
clean = data.copy()
clean = clean.replace(r'\s+', np.NaN, regex=True)
clean = clean[PREDICTORS + ['lifeexpectancy']].dropna()
for key in PREDICTORS + ['lifeexpectancy']:
clean[key] = pandas.to_numeric(clean[key], errors='coerce', downcast='integer')
clean = clean.astype(int)
predictors = clean[PREDICTORS]
targets = clean.lifeexpectancy
pred_train, pred_test, tar_train, tar_test = train_test_split(predictors, targets, test_size=.4)
print(pred_train.shape, pred_test.shape, tar_train.shape, tar_test.shape)
(33, 14) (23, 14) (33,) (23,)
Modeling and output
# Build model on training data
classifier = DecisionTreeClassifier()
classifier = classifier.fit(pred_train, tar_train)
predictions = classifier.predict(pred_test)
print('Confusion matrix:', sklearn.metrics.confusion_matrix(tar_test, predictions), sep='\n')
print('Accuracy score:', sklearn.metrics.accuracy_score(tar_test, predictions))
Confusion matrix:
[[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 1 0 0 0 0 0 0]
[0 0 0 0 0 0 1 0 0 1 0 0 0 0 0]
[1 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 1 0 0 1 0 0 0 0 0]
[0 0 0 0 0 0 0 1 0 1 0 0 0 0 0]
[1 0 0 0 0 0 1 2 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 1 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 2 1 1 0 0]
[0 0 0 0 0 0 0 0 0 0 0 1 3 1 0]
[0 0 0 0 0 0 0 0 0 0 0 0 1 0 0]]
Accuracy score: 0.130434782609
# Displaying the decision tree
from sklearn import tree
from io import StringIO
from IPython.display import Image
import pydotplus
out = StringIO()
tree.export_graphviz(classifier, out_file=out)
graph = pydotplus.graph_from_dot_data(out.getvalue())
Image(graph.create_png())
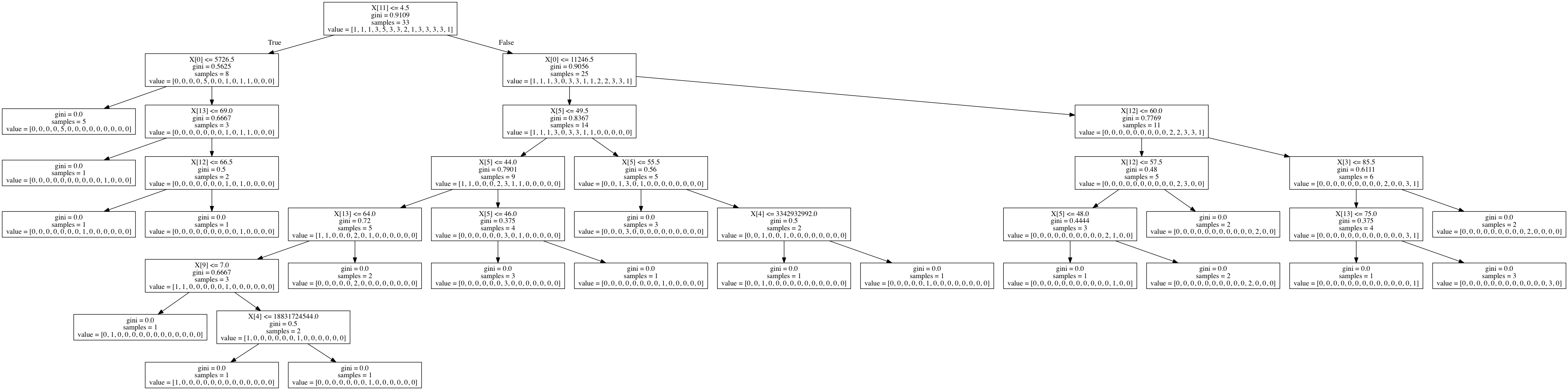
Summary
I was able to create a decision tree out of the gapminder dataset evaluating the conditions that contribute to life expectancy. A lot of data cleanup was required to generate this tree, as sklearn couldn&rsqu;t build a tree out of floats, which comprised most of my dataset.
I think the gapminder dataset is too small to build a meaningful decision tree. The accuracy score was 0.13 and the initial sample split was 8 and 25. The output is also incredibly hard to read. It would be nice to be able to replace X[0] with something like X[incomeperperson].